Ребята, серьезно, может лучше не будем?..
(вступление от автора)
Виды архитектур
CISC (англ. Complex instruction set computing, или англ. complex instruction set computer — компьютер с полным набором команд) — концепция проектирования процессоров. Имеет следующие свойства:
- Нефиксированные по длине команды
Каждая команда является "обычным числом", то есть просто hex-значение в памяти. В состав команды обычно входят её параметры, которые также имеют определенный размер. В результате размер команды сложится собственно из того набора байт (от 1 до n), которое обозначает инструкцию процессора и все сопутствующие параметры. В архитектуре CISC одна команда может быть длиной 1 байт, другая 3 байта и так далее.
- Каждый регистр имеет свою функцию
Это значит, что некоторые команды не используют какие-то особые параметры, а по умолчанию используют определенный регистр процессора. В таком случае явно такой регистр при вызове команды не указывается, а в него просто заранее кладется (из него достается) некоторое нужное значение.
- Арифметические операции требуют 1 команду
Противопоставляется первым процессорам RISC, в которых не было операций умножения и деления в угоду скорости исполнения. Таким образом, исполнение инструкции умножения на CISC архитектуре проще выполняется, но не распараллеливается во конвеерам процессора, в то время как на RISC процессорах та же инструкция представляется совокупностью других инструкций, которые соответственно можно выполнить параллельно (подробнее гугли про устройство процессора).
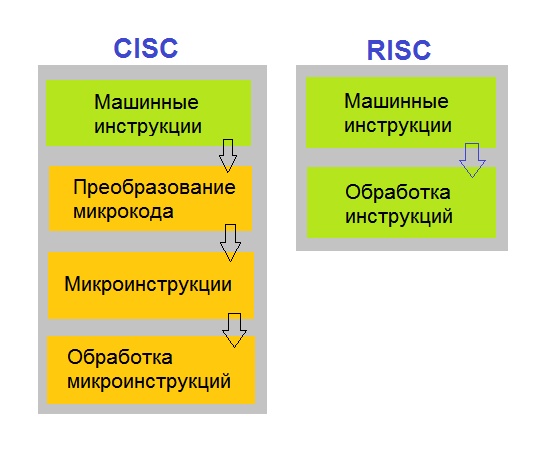
RISC (англ. restricted (reduced) instruction set computer — компьютер с сокращённым набором команд) — архитектура процессора, в котором быстродействие увеличивается за счёт упрощения инструкций чтобы их декодирование было более простым, а время выполнения — меньшим.
- Команды имеют одинаковую длину и структуру
Во-первых, так проще запоминать эти инструкции, и как они работают. Во-вторых, не надо учитывать особенности вызова той или иной команды с разными параметрами - все унифицировано. В-третьих, эти команды работают быстрее, так как занимают одинаковое количество байт и их проще запустить параллельно
- Регистров значительно больше, и они используются значительно свободнее
Дело в том, что в компьютере самой медленной является ПЗУ на жестком диске, а оперативная память считается быстрой. Но если посмотреть глубже, то для процессора оперативная память тоже является достаточно медленной, поэтому он использует КЭШ, встроенный на кристалле, а самой быстрой является память, организованная в самом процессоре на ячейках памяти, называемых СОЗУ (сверх быстрая ОЗУ).
- Специализированные команды для работы с памятью
Как уже говорилось выше, доступ к памяти штука медленная (в категориях процессорного времени), поэтому надо минимализировать использование инструкций, работающих с памятью. Если у нас есть универсальная инструкция для работы с памятью и с регистрами, то каждый раз, когда мы будет писать/читать регистр у нас будет уходить столько же времени, сколько и на чтение ячейки памяти. Поэтому команды для работы с памятью вынесены отдельно.
РОН и РСН
Как было сказано выше, у процессора есть внутренняя память. Для удобства обращения она разделена на регистры (можете воспринимать их как "переменные" или просто именованные участки памяти). Каждый регистр имеет определенный размер (зависит от архитектуры системы) и указывает на определенный участок памяти. Эти параметры являются постоянными и вы их не измените. Когда процессор работает с регистрами, это занимает у него намного меньше времени, чем когда он работает с памятью.Но программист не имеет доступа ко всем регистрам, а только к некоторым. Из множества доступных можно выделить две большие группы: регистры общего назначения (РОН) и регистры специального назначения (СР или РСН). Первые нужны для выполнения любых "пользовательских" операций, другими словами, в них можно свободно писать данные и читать из них, а также выполнять над ними любые доступные операции. Вторая группа регистров используется для "системных" целей: хранение текущего состояния процесса, номер следующей выполняемой инструкции, указатель на стек и так далее.


Виды инструкций

У каждого процессора есть "стандартный набор команд" (он примерно одинаков для подавляющего большинства архитектур): арифметические команды, булева алгебра, вызовы инструкций и условные переходы и т. д. Но кроме этих, есть дополнительные списки команд, относящиеся к конкретному процессору или семейству процессоров. Эти инструкции решают строго определенный круг задач и предназначены для оптимизации сложных действий и ускорения работы. К таким командам можно отнести: MMX, SSE, SSE2 и т. д.
Стек
Регистры - участки памяти для хранения данных в процессе их обработки. Это понятно. Но куда девать параметры функции при её вызове, "старые" значения регистров при их изменении, прочие временные данные? Для этих целей служит стек: участок из выделенной просцессу памяти, используемый программой для вышеперечисленных, и не только, целей. "Как работает стек? Почему это выделенная отдельно область памяти?" - спросите вы. Правильно спросите. Стек работает по принципу LIFO: что последнее в него положил, то первое можешь достать. Например, представьте женскую сумочку. На её дно мы положим ключи от дома, сверху одноразовые салфетки, и сверху ключи от машины. Теперь чтобы достать ключи от дома надо сначала достать ключи от машины, потом достать одноразовые салфетки, и только потом можно будет достать ключи от дома. Подробнее принцип работы представлен на картинке.
Кроме того, в некоторых системах принято передавать аргументы функций (то что вы на C++ пишете в скобочках после имени функции) через стек. Ещё некоторые функции меняют значения регистров, и если не сохранить их состояние предварительно, то можно нарушить всю работу программы. При осуществлении всех вышеперечисленных способов использования стека, возникает неоднозначный момент: основная "ветка" выполнения может иметь указатель стека не в том месте, где закончилось выполнение вызванной функции. В таких случаях стек "выравнивают", то есть устанавливают указатель на то значение, которое было до вызова функции, иначе следующий элемент стека может просто потеряться и программа перестанет работать.
Вызов функции
"Ага. И как понять, нужно ли мне выравнивать стек и как с ним вообще работать?"