Каждый из нас обязательно хоть раз программировал. Без этого на CTF не жизнь - а тоска, потому что делать все ручками не получится. Все мы, конечно, используем и хвалим свой язык и своё видение кода, но при этом приходится сталкиваться с чужими проектами и даже с неизвестными языками. Для того, чтобы такая встреча не переросла в неприятность, я попытаюсь сделать короткий обзор по миру программирования.
 Статический анализ кода - это когда код проверяется на ошибки без компиляции и запуска. В принципе, когда IDE показывает вам, что "вы там-то забыли скобочку", то это простейший вариант статического анализа. Обычно среда разработки имеет некоторый набор собственных инструментов для анализа безопасности кода, но тем не менее стоит применять и продукты, специально "заточенные" под это.
Статический анализ кода - это когда код проверяется на ошибки без компиляции и запуска. В принципе, когда IDE показывает вам, что "вы там-то забыли скобочку", то это простейший вариант статического анализа. Обычно среда разработки имеет некоторый набор собственных инструментов для анализа безопасности кода, но тем не менее стоит применять и продукты, специально "заточенные" под это.
Динамический анализ кода - код проверяется на ошибки при помощи некоторого тестирования. Данный способ тоже поддерживается некоторыми IDE, и также существуют сторонние утилиты, которые писались исключительно с этой целью. Грубо говоря это проверка во время выполнения, путем ввода различных комбинаций входных данных и манипулирования различными частями приложения.
 Каждый язык обладает своими уникальными способностями и преимуществами над другими языками, но реальность такова, что требуемый функционал в полном объеме не содержится ни в одном языке. В таком случае при решении задачи используют связку из нескольких языков, которые в совокупности удовлетворяют предложенным требованиям. Такая межъязыковая связь может быть реализована с использованием нескольких различных техник.
Каждый язык обладает своими уникальными способностями и преимуществами над другими языками, но реальность такова, что требуемый функционал в полном объеме не содержится ни в одном языке. В таком случае при решении задачи используют связку из нескольких языков, которые в совокупности удовлетворяют предложенным требованиям. Такая межъязыковая связь может быть реализована с использованием нескольких различных техник.
Часто можно увидеть в программном коде драйверов на C вставки, сделанные на ассемблере. Так происходит потому, что некоторые места в программе являются критичными по времени выполнения или код требует прямого взаимодействия с регистрами процессора.
Другой вариант использования нескольких языков, это написание различных модулей. При этом модули компилируются под определенную систему и используются в программе связанно. Этот подход можно встретить в интерпретаторе языка python, в котором некоторые модули написаны непосредственно на C, а некоторые - на промежуточном языке для PVM. Такой подход используется если среда разработки не поддерживает вставки на других языках.
Также бывают различные платформы наподобие .NET и QT, которые позволяют писать на различных языках, код которых будет транслирован в байткод (промежуточный язык среды исполнения) и соответственно выполнен как единое целое.
Чтобы не копипастить из Вики и прочих ресурсов, а также не переписывать заново учебники, я лишь перечислю основные моменты, и укажу ссылки, с которых можно начать ознакомление с той или иной темой.

Первоначально, языки удобно делятся на две большие группы: низкоуровневые и высокоуровневые. К сожалению делятся не всегда однозначно. К низкоуровневым можно отнести различные "диалекты" ассемблера, а также промежуточные языки разработки наподобие CIL: в общем все, что работает с командами реального или виртуального процессора. К высокоуровневым - все остальные.
Также существует классификация по парадигме программирования. Это большая и скучная классификация, и я не буду приводить её здесь. Отмечу лишь то, что каждая категория создавалась для упрощения написания программ, решающих определенную категорию задач. Отсюда делаем вывод, что код на любом процедурном языке можно переписать на другом процедурном языке (конечно, это все формально) - языки из одной группы в принципе взаимозаменяемы.
Ещё языки бывают компилируемые и интерпретируемые. Для первых исполняемый код создается сразу для всей программы, а для вторых - пошагово, для каждого шага отдельно.
Попадаются и экзотические языки. Их огромное количество, и организаторы игр очень любят их применять, проверяя эрудицию участников.
К чему это всё? В CTF встречаются языки всех типов, видов и даже их комбинации. Для решения задач из этой области надо понимать зачем какой язык существует, как он работает, знать синтаксис и самые частые ошибки, допускаемые при программировании.
Классификация языков
Также существует классификация по парадигме программирования. Это большая и скучная классификация, и я не буду приводить её здесь. Отмечу лишь то, что каждая категория создавалась для упрощения написания программ, решающих определенную категорию задач. Отсюда делаем вывод, что код на любом процедурном языке можно переписать на другом процедурном языке (конечно, это все формально) - языки из одной группы в принципе взаимозаменяемы.
Ещё языки бывают компилируемые и интерпретируемые. Для первых исполняемый код создается сразу для всей программы, а для вторых - пошагово, для каждого шага отдельно.
Попадаются и экзотические языки. Их огромное количество, и организаторы игр очень любят их применять, проверяя эрудицию участников.
К чему это всё? В CTF встречаются языки всех типов, видов и даже их комбинации. Для решения задач из этой области надо понимать зачем какой язык существует, как он работает, знать синтаксис и самые частые ошибки, допускаемые при программировании.
Способы анализа кода
Динамический анализ кода - код проверяется на ошибки при помощи некоторого тестирования. Данный способ тоже поддерживается некоторыми IDE, и также существуют сторонние утилиты, которые писались исключительно с этой целью. Грубо говоря это проверка во время выполнения, путем ввода различных комбинаций входных данных и манипулирования различными частями приложения.
Распространенные ошибки
Условно разобьем работу программы на 3 этапа: ввод данных, обработка данных, вывод данных. Накосячить можно на любом из этих уровней, что представляет радость для взломщика и жуткий батхерт для разработчика.
 При написании программ, равно как и при их отладке или исследовании, стоит обратить особое внимание на то, как и в чем написан код. Во-первых существует бесчисленное множество различных инструментов, которые позволяют максимально облегчить жизнь разработчику. Самыми значимыми из них являются фреймворки, потому что они уже содержат в себе множество инструментов налаженных и настроенных под работу в комплексе. Фреймворки имеют гибкие настройки и различные маленькие "секретики", по которым можно с высокой вероятностью установить: в чем именно был написан код. Иногда это позволяет получить из бинарного файла исходный код.
При написании программ, равно как и при их отладке или исследовании, стоит обратить особое внимание на то, как и в чем написан код. Во-первых существует бесчисленное множество различных инструментов, которые позволяют максимально облегчить жизнь разработчику. Самыми значимыми из них являются фреймворки, потому что они уже содержат в себе множество инструментов налаженных и настроенных под работу в комплексе. Фреймворки имеют гибкие настройки и различные маленькие "секретики", по которым можно с высокой вероятностью установить: в чем именно был написан код. Иногда это позволяет получить из бинарного файла исходный код.
Немаловажным для программиста будет знание паттернов программирования и способов тестирования. Все это позволит быстрее писать правильный код, лишенный множества маленьких, но очень важных багов, а также лучше разбираться в чужих сорцах.
Осведомленность об особенностях работы системы, под которую написана программа, и наличии различных консольных утилит, предоставляемых ОСью по умолчанию, будет плюсом, потому что нередко для упрощения работы приложения (чтобы не городить велосипедов), программа передает данные для обработки другой утилите.
Ввод данных
Самое очевидное - отсутствие проверки входных данных. То есть, вообще никакой проверки: последствия очевидны. Чуть менее очевидное - недостаточная проверка: она есть, но не охватывает все возможные комбинации входных данных. В высшей степени дурным тоном является исполнение введенных пользователем команд без фильтрации на ввод. Проверка длины введенных данных поможет спастись от переполнения различных структур (буфер, стек и т. д.).Обработка данных
Здесь поле для взращивания багов вообще безгранично. Особо опасными являются участки кода, добавленные для отладки, но впоследствии не удаленные. Отсутствие проверки типов данных и обработки ошибок, неправильное освобождение памяти и ресурсов, самопальные алгоритмы шифрования и множество других проблем могут сыграть злую шутку с самонадеянным программистом (на CTF соревнованиях "программы именно таких программистов" представляются для взлома).Вывод данных
И снова отсутствие всякой проверки того, что выводим из недр программы, грозит нам потерей некоторой конфиденциальной или полезной взломщику информации. Слишком полный вывод ошибок тоже может обернуться против нас: вместе с кодом ошибки часто появляются данные, позволяющая рассекретить наш "черный ящик" и структуру информации в нем.Способы написания кода
Немаловажным для программиста будет знание паттернов программирования и способов тестирования. Все это позволит быстрее писать правильный код, лишенный множества маленьких, но очень важных багов, а также лучше разбираться в чужих сорцах.
Осведомленность об особенностях работы системы, под которую написана программа, и наличии различных консольных утилит, предоставляемых ОСью по умолчанию, будет плюсом, потому что нередко для упрощения работы приложения (чтобы не городить велосипедов), программа передает данные для обработки другой утилите.
Обфускация и деобфускация
Когда разработчик пишет код, он заботится о соответствии некоторым стандартам
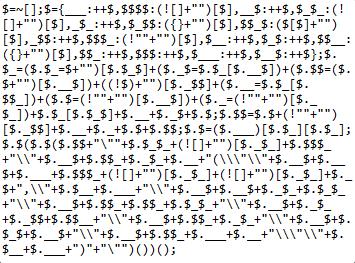 оформления. Тогда проект можно будет легко поддерживать и развивать, новые люди смогут быстро влиться в разработку. Но это не всегда хорошо.
оформления. Тогда проект можно будет легко поддерживать и развивать, новые люди смогут быстро влиться в разработку. Но это не всегда хорошо.
Предположим, есть некоторый критичный к безопасности участок кода. Он был написан один раз, оттестирован и отлажен и больше меняться не будет. Также существует вполне реальная возможность того, что кодом завладеет злоумышленник, поэтому код делают нечитаемым - обфусцируют. Для этого существует множество способов: добавление мусорных строк кода, изменение всех переменных и функций на имена с похожим написанием, повторное использование всех возможных имен, отсутствие форматирования кода и прочее. По большому счету компилятору не важно как написан и отформатирован код, потому что от изменения оформления функционал не меняется. Чаще всего обфусцируют интерпретируемые языки, потому что программный код сохраняется в первоначальном виде и наиболее уязвим.
Процедура деобфускации не всегда является тривиальной задачей, поэтому полностью автоматизировать данный процесс не удается: всегда нужно вручную рассматривать спорные места, и тем более давать переменным и функциям осмысленные имена. В целом обфускация является эффективным методом защиты кода, но делает практически невозможным его поддержку.
Предположим, есть некоторый критичный к безопасности участок кода. Он был написан один раз, оттестирован и отлажен и больше меняться не будет. Также существует вполне реальная возможность того, что кодом завладеет злоумышленник, поэтому код делают нечитаемым - обфусцируют. Для этого существует множество способов: добавление мусорных строк кода, изменение всех переменных и функций на имена с похожим написанием, повторное использование всех возможных имен, отсутствие форматирования кода и прочее. По большому счету компилятору не важно как написан и отформатирован код, потому что от изменения оформления функционал не меняется. Чаще всего обфусцируют интерпретируемые языки, потому что программный код сохраняется в первоначальном виде и наиболее уязвим.
Процедура деобфускации не всегда является тривиальной задачей, поэтому полностью автоматизировать данный процесс не удается: всегда нужно вручную рассматривать спорные места, и тем более давать переменным и функциям осмысленные имена. В целом обфускация является эффективным методом защиты кода, но делает практически невозможным его поддержку.
Межъязыковое программирование
Часто можно увидеть в программном коде драйверов на C вставки, сделанные на ассемблере. Так происходит потому, что некоторые места в программе являются критичными по времени выполнения или код требует прямого взаимодействия с регистрами процессора.
Другой вариант использования нескольких языков, это написание различных модулей. При этом модули компилируются под определенную систему и используются в программе связанно. Этот подход можно встретить в интерпретаторе языка python, в котором некоторые модули написаны непосредственно на C, а некоторые - на промежуточном языке для PVM. Такой подход используется если среда разработки не поддерживает вставки на других языках.
Также бывают различные платформы наподобие .NET и QT, которые позволяют писать на различных языках, код которых будет транслирован в байткод (промежуточный язык среды исполнения) и соответственно выполнен как единое целое.